Building Semantic Knowledge Graphs with LLMs: Inside MyFeeds.ai's Multi-Phase Architecture
The post Establishing Provenance and Deterministic Behaviour in an LLM-Powered News Feed (first MyFeeds.ai MVP) mentions the use of LLMs to go from an RSS Feed entry all the way to an personalised blog post, but what do those entities look like? and more importantly, how do we have provenance, explainability and determinism from this workflow?
Let's take for example the CEO (19 Mar) post which looked like this:

As you can see, the intro text is focused on the CEO persona, and in the 50x available articles from the Hacker News RSS feed used, the Future-Proofing Business Continuity: BCDR Trends and Challenges for 2025 article was selected, which looks like this:

Since we are using the RSS feed, it all starts with the XML content:
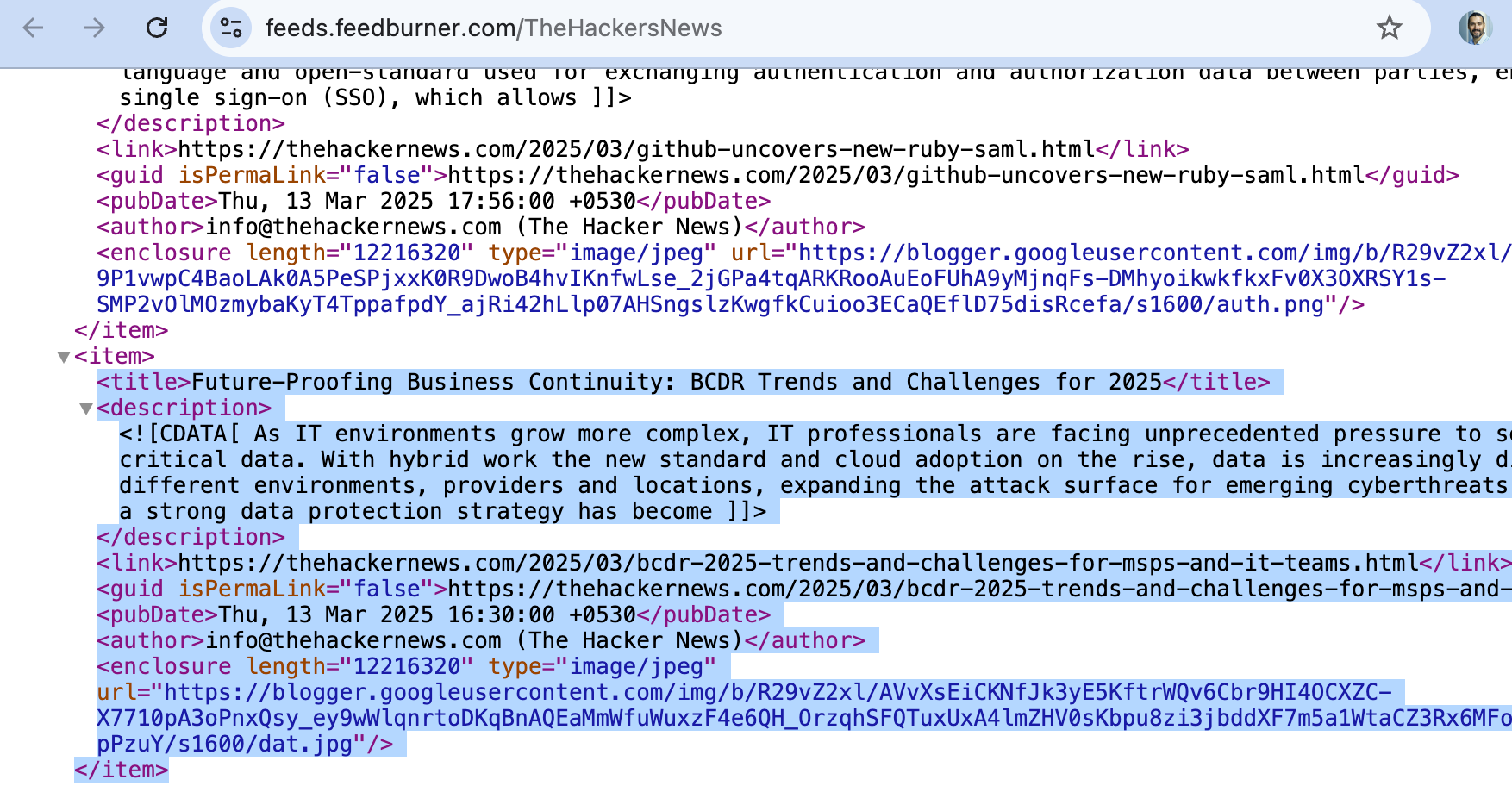
Note: In this first MVP we are only using the text of the title "Future-Proofing Business Continuity: BCDR Trends and Challenges for 2025" (I also created a similar workflow using the description, but the title was already working quite well)
What didn't work: using one LLM call to create the output
On the personalisation path, the first thing I tried was to create a prompt that had:
- the entire RSS feed content (i.e the titles and descriptions)
- a description of the user's persona (in this case a CEO)
- a description of the desired output (for example a news digest)
This was easily done by converting the RSS content into a 'prompt friendly' text based representation:
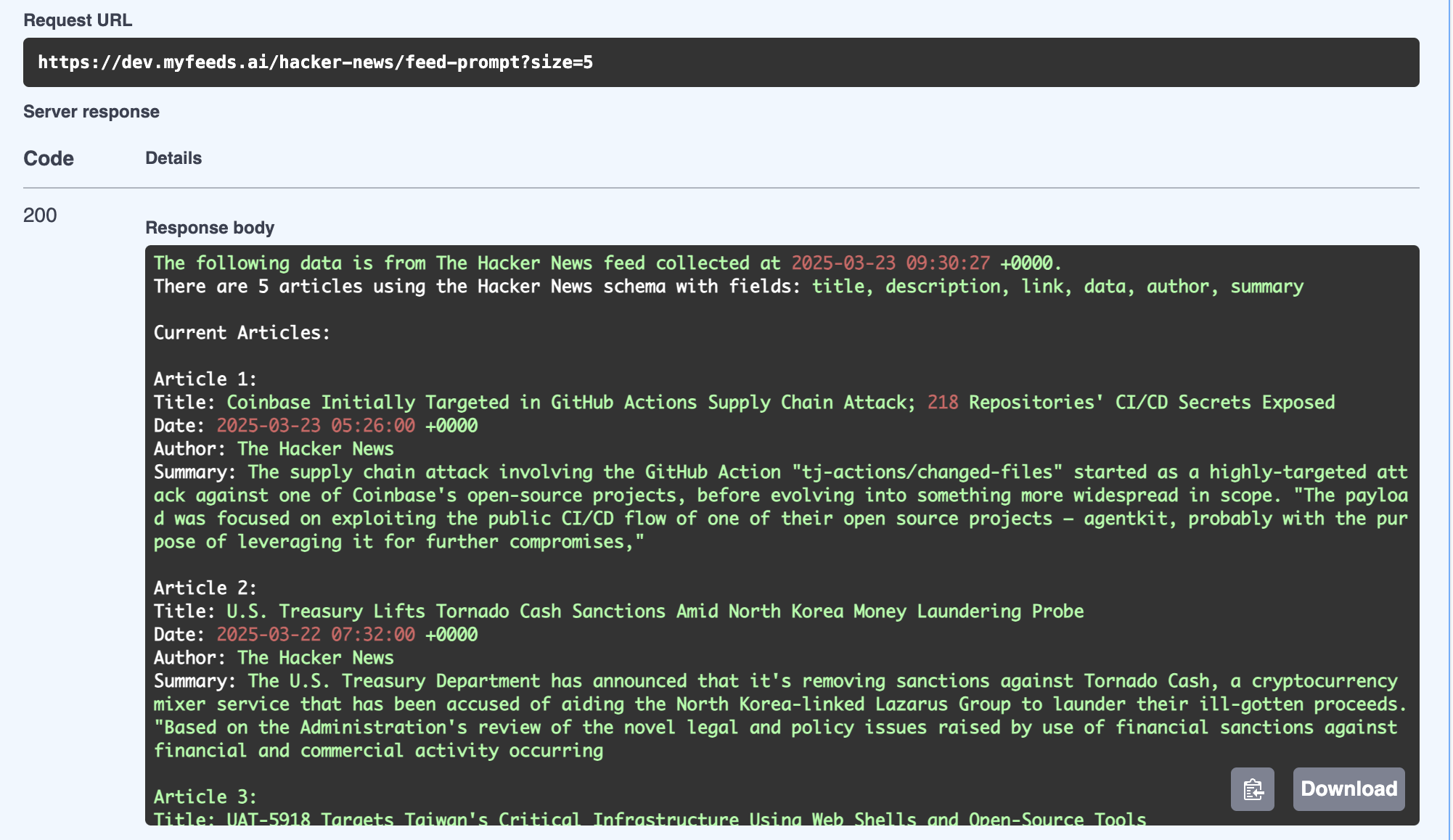
.... which I could easily add to one of my Cyber Boardroom personas (in this case a CEO):
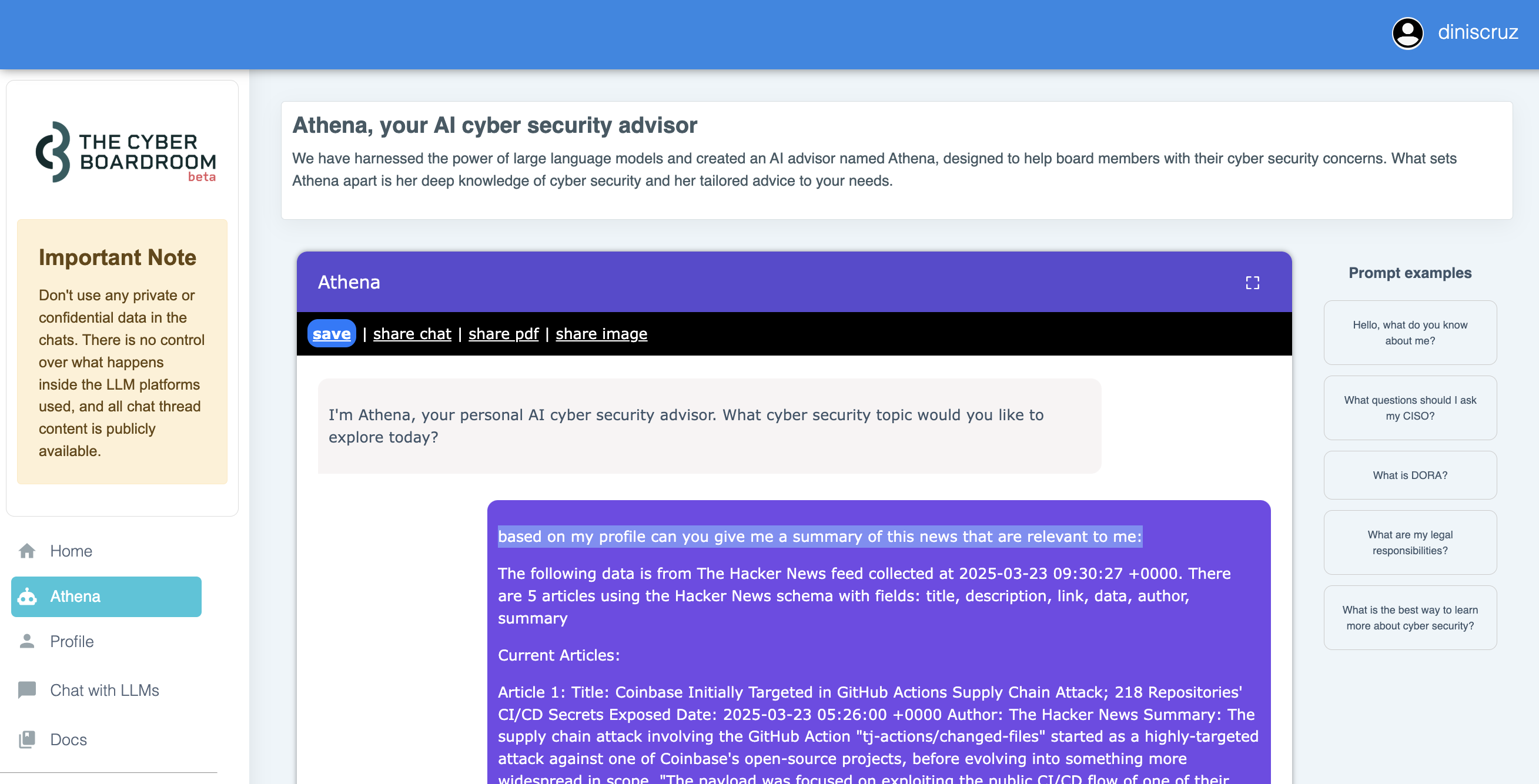
.... resulting in something like this:
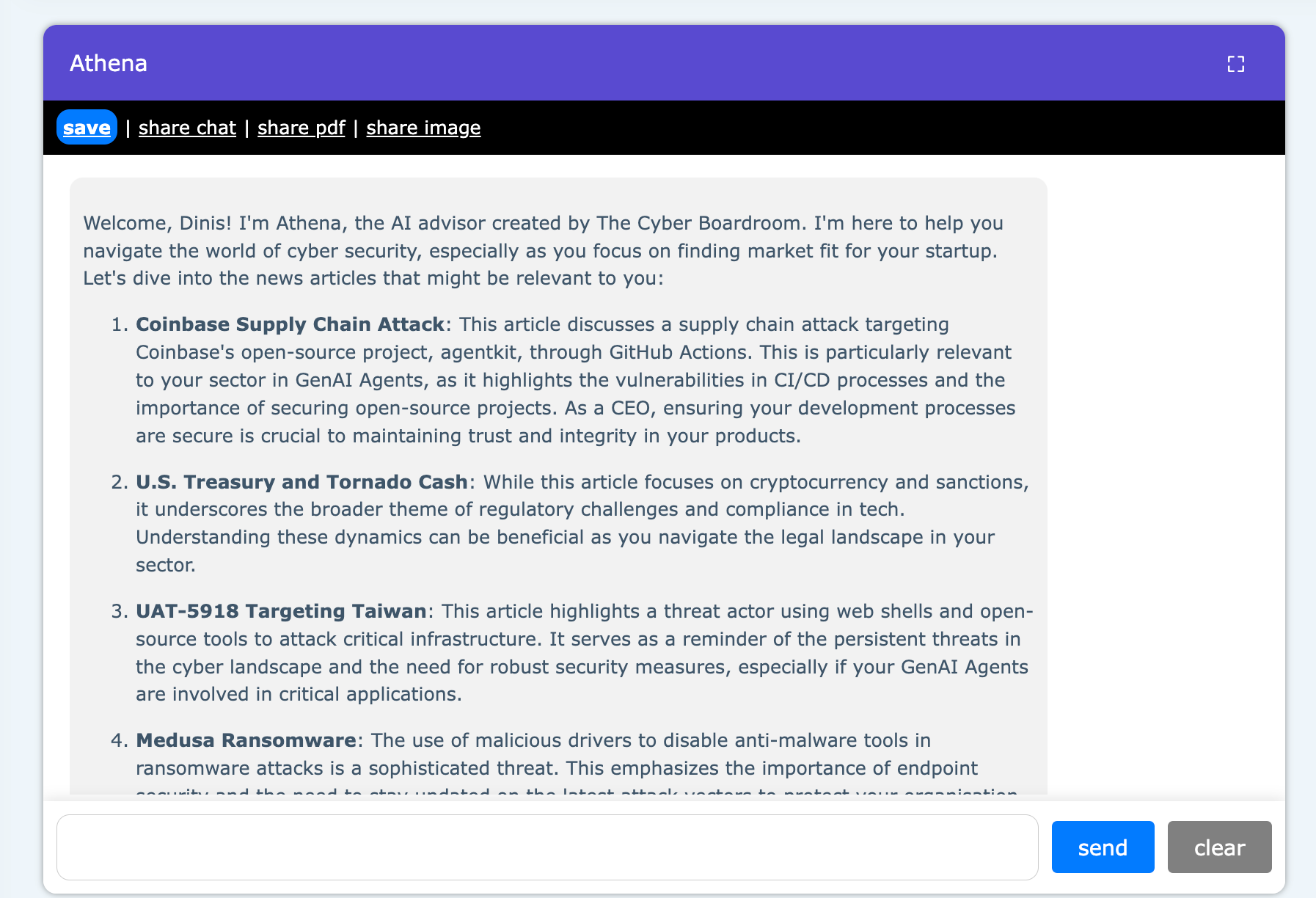
Although this kinda works, when using the 50x RSS articles and asking the LLM to pick the most relevant 5x, I had a large number of very important problems, challenges and concerns: (which btw are the same ones faced by the companies/services that have been trying to create personalised news feed, with limited success) :
- Explainability: How do I explain exactly how and why those specific 5x articles were selected
- Provenance: How can I connect each article, statement, opinion, and more importantly, each fact, into it's original source
- Determinism: How can I make sure that the results are deterministic and repeatable (i.e. same inputs should produce the same output)
- LLM is doing too much: since we can't look inside the LLM and understand how it arrive at its conclusions, this is a good example (like in most Agentic solutions these days) where the LLM is just doing too much in one step
Semantic Knowledge Graphs
After a number of experiments, following on my personal theme that 'everything is really just graphs and maps' and inspired by the great work/thinking done by the semantic web community, the solution that worked really well was to use Semantic Knowledge Graphs
But the problem I always had when I created large graphs (for example when using Jira as a GraphDB) was how to scale the graph creation, curation and connection.
As explained in detail here in mvp.MyFeeds.ai uses 4 stages of LLM processing:

Let's look at each of these stages in action
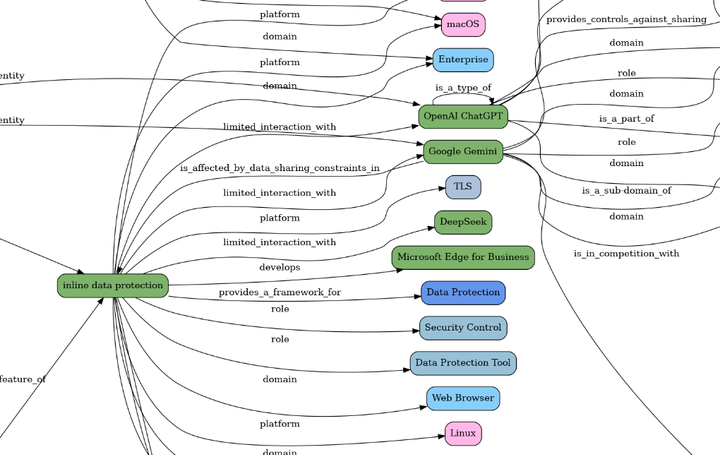
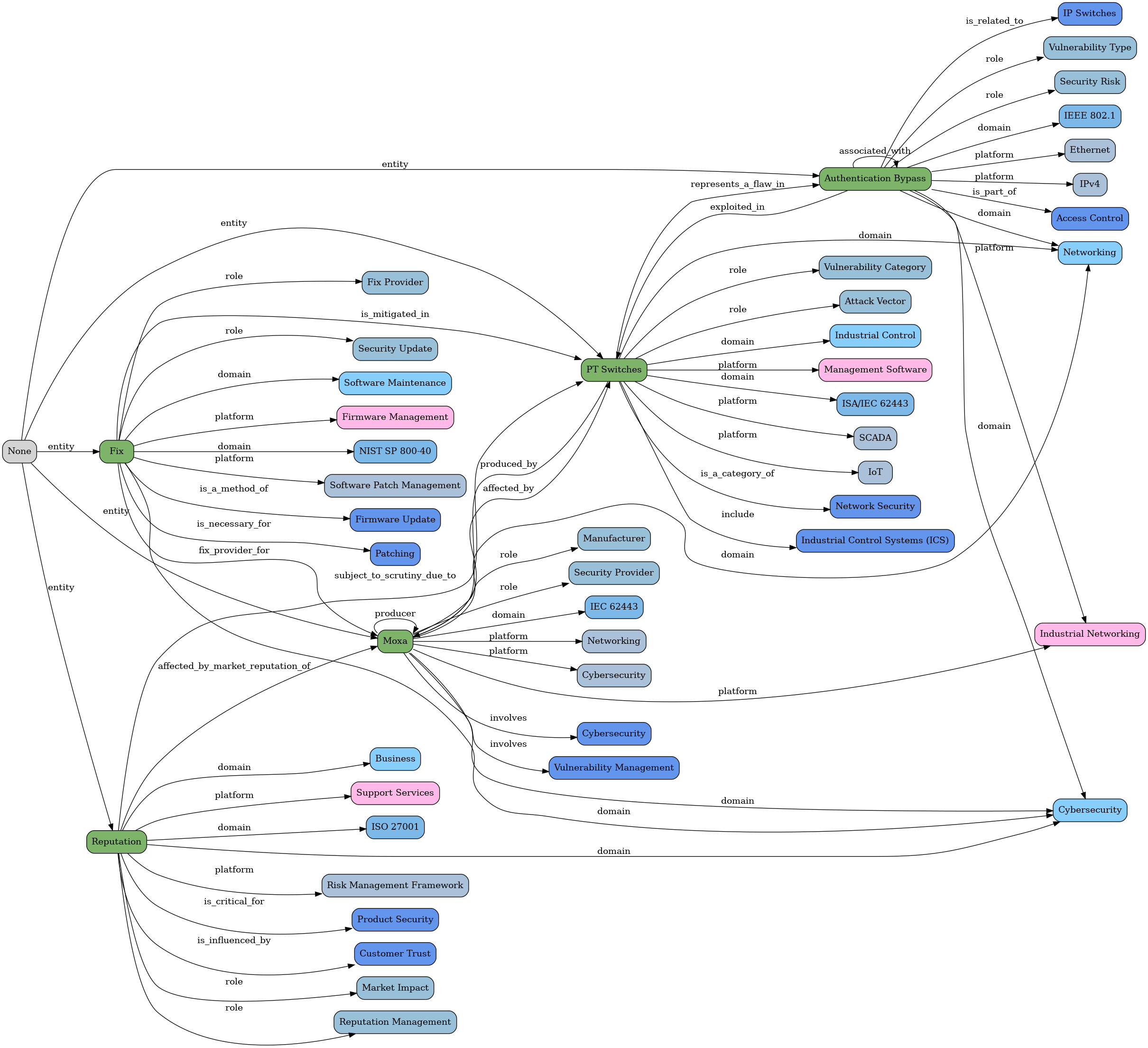
Phase 1: Entity & Relationship extraction
From the feed's RSS the following JSON file is created which is basically a representation of a Python object with the same fields:
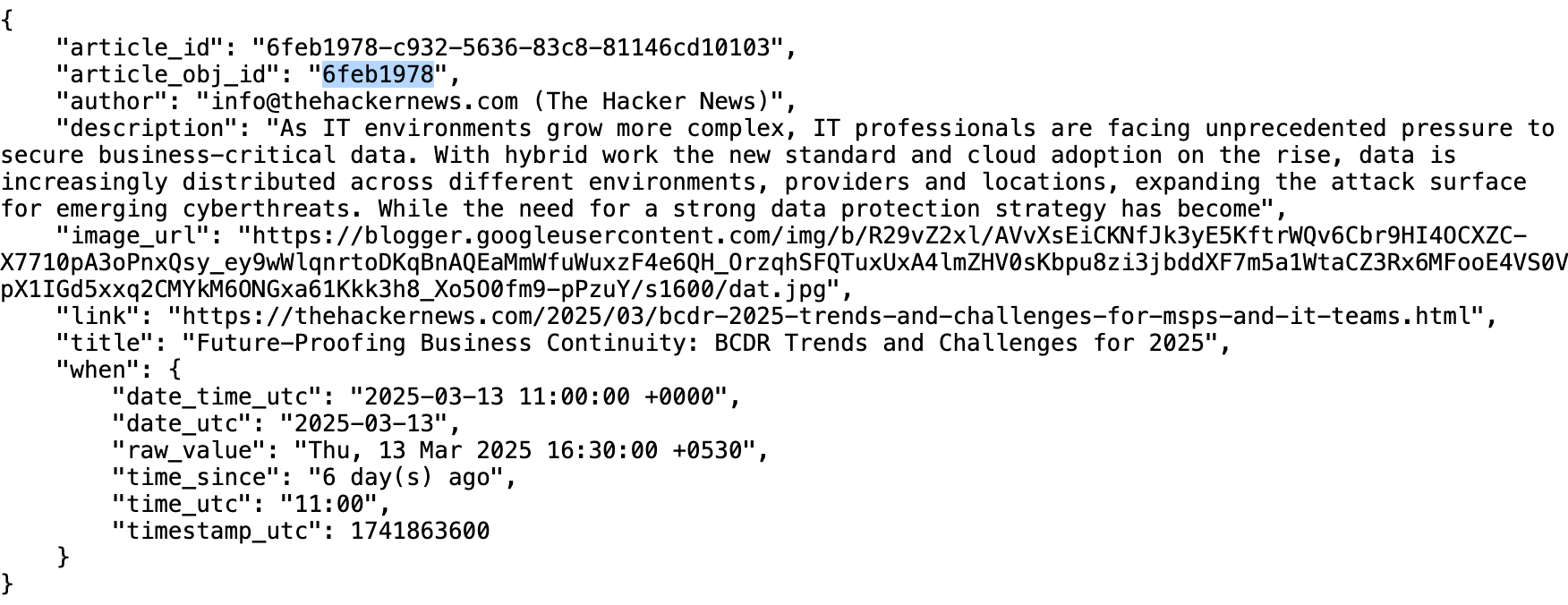
From this data the two fields that we are going to use is the article_obj_id (in this case "6feb1978") and the title value (in this case "Future-Proofing Business Continuity: BCDR Trends and Challenges for 2025")
Here is the System Prompt for this first LLM call:

What is very important and powerful is that for these calls we are using OpenAI's structured outputs where we are able to create set of Python classes which are then provided as the schema to be used by the LLM responses (i.e. we don't get raw text back from the LLM call, we get nicely typed JSON/Python objects)
Here are the classes (from the MGraph-DB project) used in this 'entity text extraction' LLM:



Which look like this (when created by the LLM)

Note: at the moment (for this first MVP) we are not providing the LLMs any Ontology or Taxonomy to follow, we are basically letting the LLM pick the best relationships, which it already does a pretty good job at. But as we move into a much more deterministic output, based on human feedback, we will be providing a much more explicit set of entities and relationships to use
The next step is to convert this JSON/Python object into a MGraph-DB object (i.e. nodes and edges), which looks like this

Note: MGraph-DB is the Serverless Graph database that I recently published which provides a critical part of this workflow (in this case the ability to easily manipulate and merge those JSON objects as nodes and edges). For more details see: MGraph-AI - A Memory-First Graph Database for GenAI and Serverless Apps
One of the areas that I always put a lot of coding effort in, is the visualisation of graphs, since without it, I find that I can't really understand and visualise what the graphs actually look like.
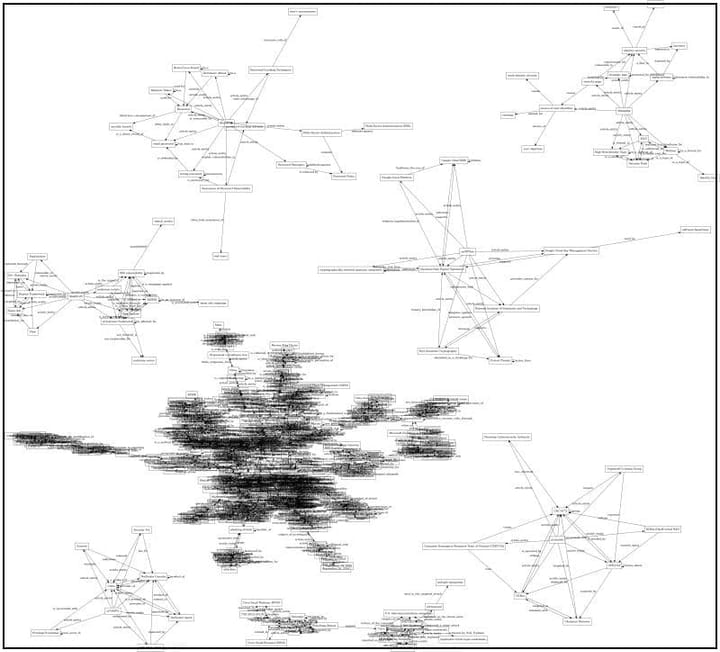
So in this case, here is the DOT/Graphviz visualisation all the relationships extracted:
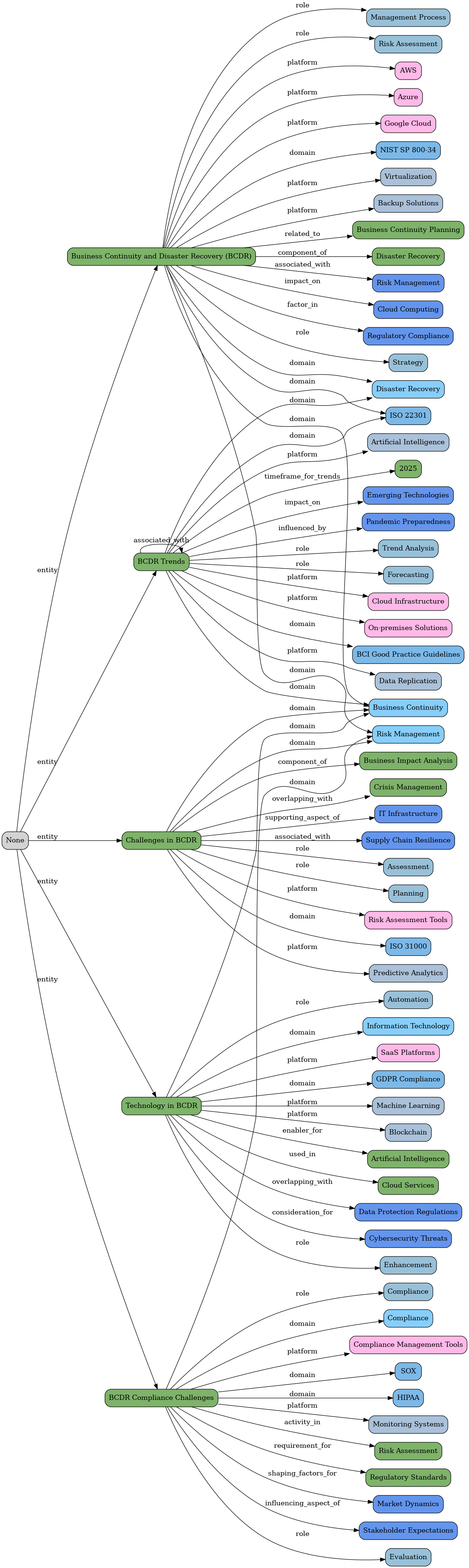
For reference here is the graph for the "Critical Authentication Bypass Vulnerability Discovered in Moxa PT Switches" which is another one of the articles shown in the CEO post
But since we can't really feed these JSON or Images to an LLM (well ... we could ... but it wouldn't be very efficient and it would introduce a big area for hallucinations), we use the the MGraph-DB Tree_Values exporter to create this compressed LLM friendly representation (also for this first MVP, I'm only using the Entities relationships from the graph above)
The image below shows the graph tree for this article in the middle of the bigger graph tree text (which is the one that contains all 50x articles from the RSS feed, that is then used in Phase 3)

Note: when working with LLMs it is very important to think about the best way to 'communicate' with the LLMs, which in this case was about how to create a representation of the graphs nodes and edges in a format that the LLMs can understand (while preserving the nodes and edges relationships), and in this case the simple tree view you can see above did the trick.
Phase 2: Persona Graph Construction
Next step is to create the equivalent graph for the target persona, in this case the CEO, which starts with this (for now hard-coded) CEO description:

Then using this LLM prompt:

... and these schemas:



... we get these set of entities mappings

... which looks like this
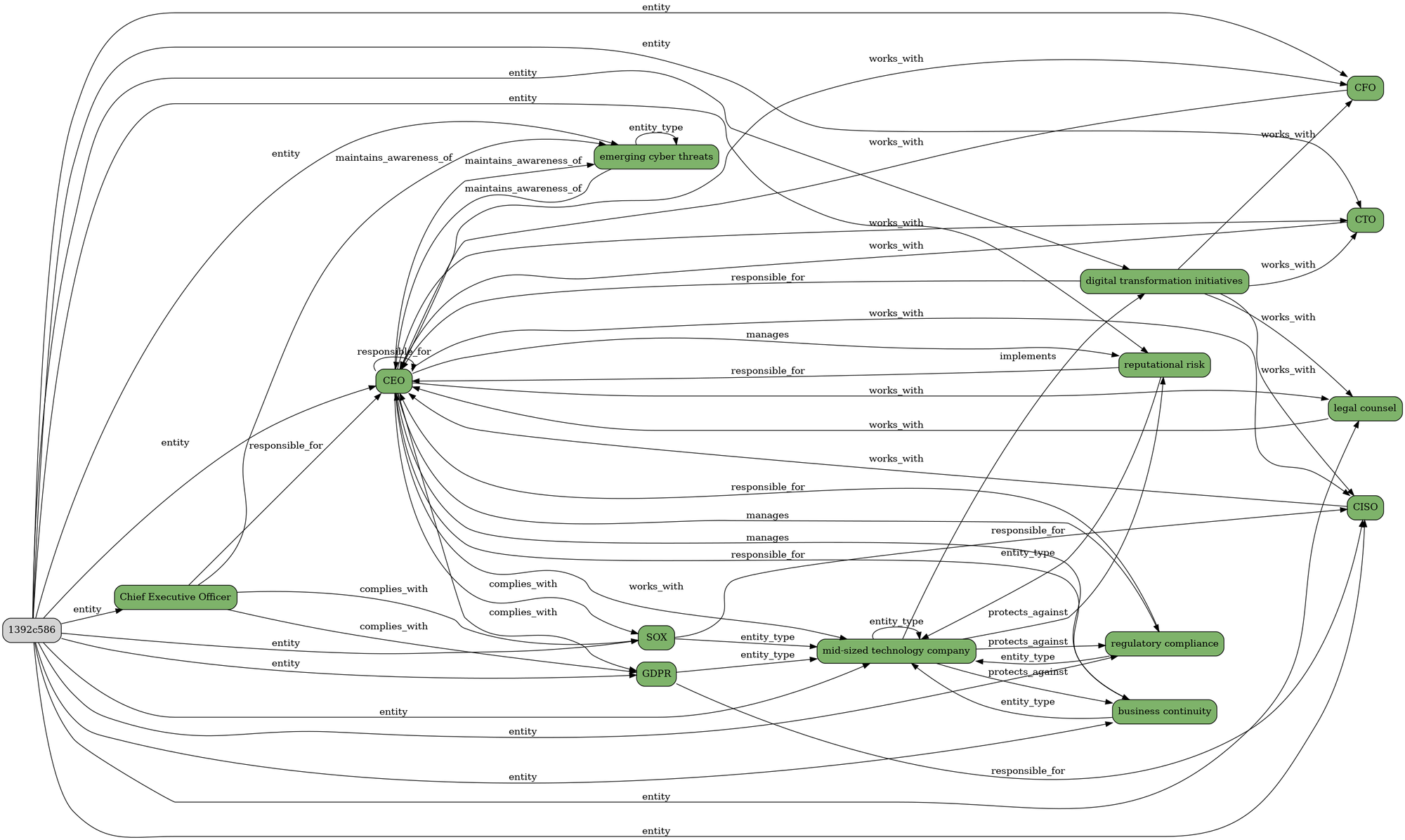
... and like this, when using the MGraph-DB Tree_Values exporter to create an LLM friendly representation:

Phase 3: Relevance Mapping
Once we have the entities for the Article and for the Persona, the key question is how do we connect them?
Note: This step should eventually not be needed once we provide a strong ontology and taxonomy to the LLM extraction steps (since we would be able to do the same by just navigating the graphs), but at this stage since we are letting the LLMs to freely define the entities and the relationships, we need a way to 'connect them', which is what this step is
Using this system prompt:

... and this user prompt (where we will include the previously created "Personas Graph Tree" and the "50x articles Graph Tree") :

... and this schema:

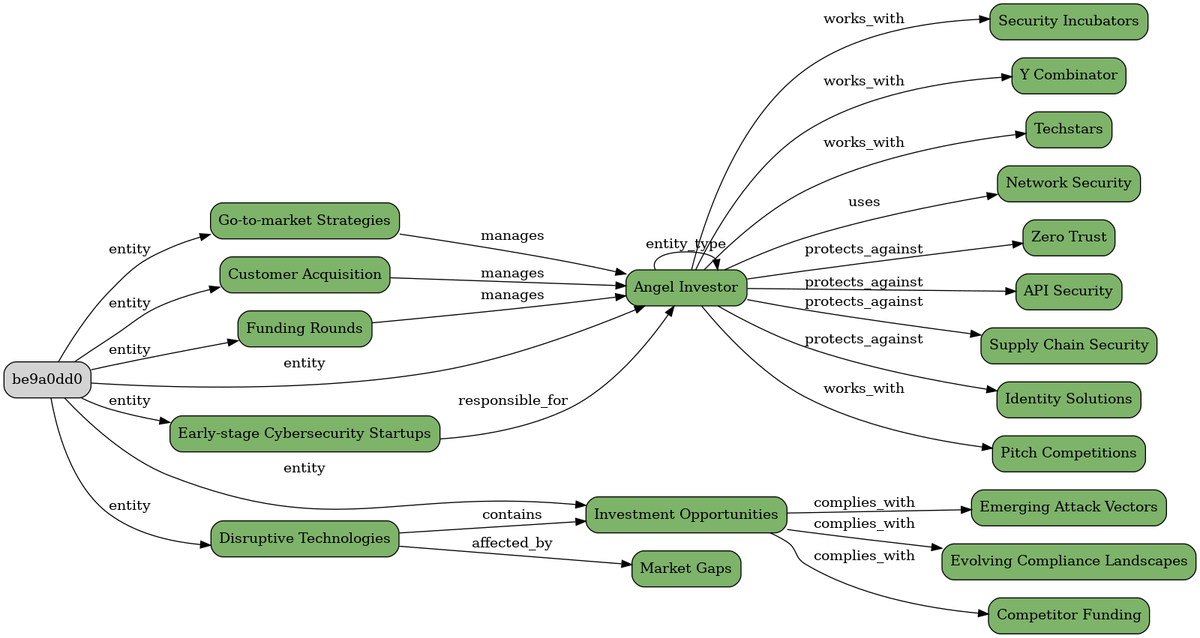
... we get these mappings:

In the image above we can see that we are looking at the mappings for the article_id for this RSS article (in this case. "6feb1978"), with 3 entities matches and an an overall score of 8.5
What is very important here are the persona_entity and the article_entity values, since they are the connections between the "Persona's entity graph" and the "Article's entity graph"
Note: although this workflow already provides good results and just about no hallucinations (since the LLM is only working on the data that was provided), my current thinking is that this is still doing 'too much' and it will be better to extract the entities per article (vs dealing with all articles in one go). This will provide better explainability and allow for more interesting use cases
Also important is that in the JSON/Python file created by this Phase 3, we also include the markdown text of the original article:
This is done in order to make it easy (and efficient) for the Phase 4 workflow prompt creation step
What is very powerful is that we now have the list of 5 articles (from the RSS feed 50) that are relevant to a particular persona (in this case a CEO), containing full provenance and explainability.
Phase 4) Personalise Summary Generation
The final use of the LLMs is in the translation of the selected articles (and connected entities) into personalised blog post.
Using this system prompt:

... and this user prompt:


... and this schema:
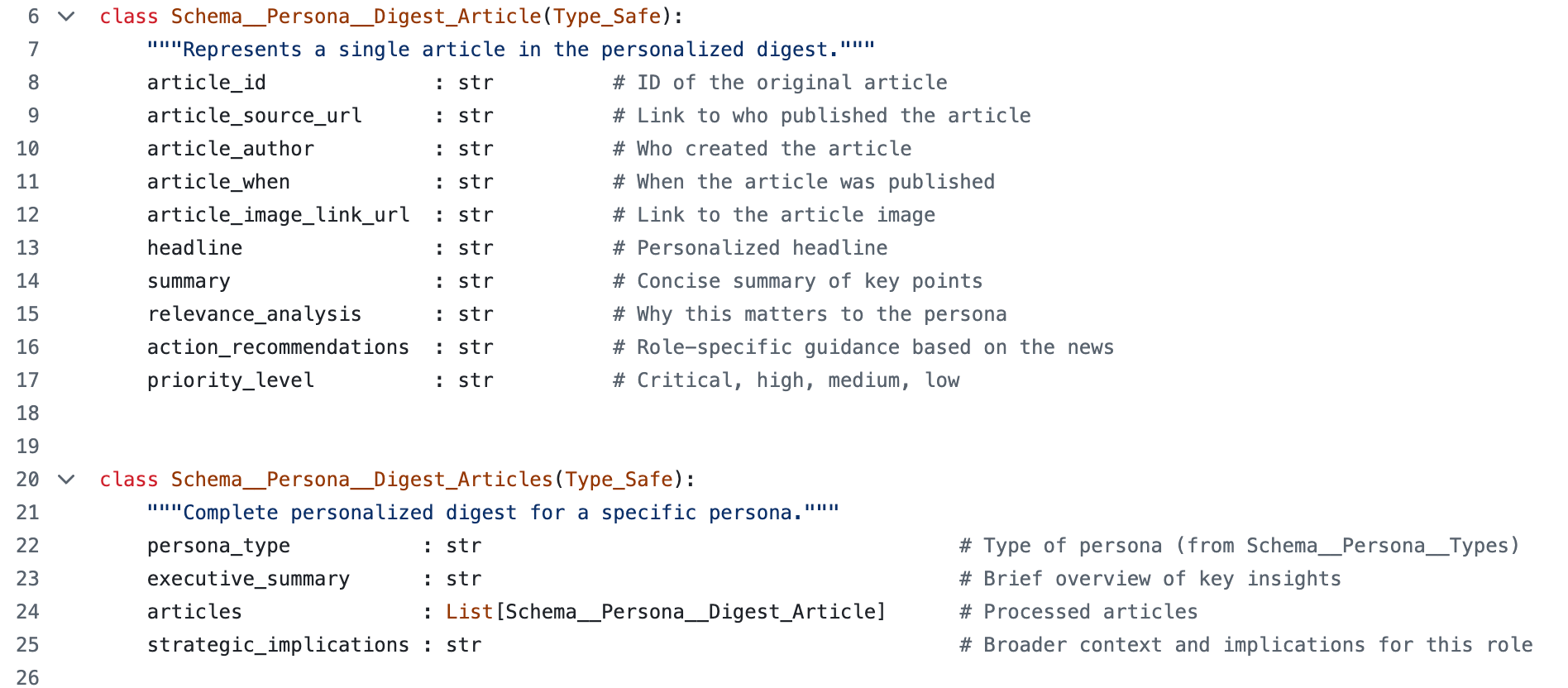
... we get this JSON/Python object:

What is very powerful here is that, as before, we are not getting raw text from the LLM , we are getting a set of nicely structured JSON/Python objects which can then be used to create the output in a much more controlled and effective way.
For example the workflow that executes this Phase 4, also creates for this persona the HTML:

... and the Markdown code:

This is what the HTML looks like (when loaded directly from the S3 bucket used to hold all the files shown here):

Ghost Publishing
The final step is to publish this article using the Ghost platform:
... to https://mvp.myfeeds.ai/ceo-19-feb/ , which looks like this:

Note: in this first MVP, the publishing was done manually (i.e. copy and paste of the persona's HTML shown above), but the key reason I picked the Ghost platform was because it has a really good API, which will make this step easy to implement
Personalising to an actual persona (and keep it private)
At the moment, the MyFeeds.ai workflows all work on a predefined set of personas and all the data is publicly available (via REST API), so what about when we want to further personalise the result and keep it private?
That is where the Cyber Boardroom comes into play, since I've already added there powerful user authentication and "multiple personas per user" capabilities.
The idea is that MyFeeds provides the key data primitives that can then be further processed, customised and personalised at the Cyber Boardroom
Also important will be to add the human-in-the-loop feedback workflows, where these first set of Ontologies and Taxonomies created by the LLMs will be fine tuned and corrected, providing a scalable way to create and maintain Semantic Knowledge Graphs.
In conclusion
I'm really happy with this workflow, since it represents where I believe GenAI and LLMs can make a massive difference: Semantic Graphs creation, curation and maintenance, with Human-in-the-loop workflows
The other key principle that you can see in action in these workflows is the: "Only use LLMs for what they are the only option, and for everything else use code"
As a good example of how much key infrastructure is still missing from the LLMs code generation work, it took me 3 months of development and lots of experimentation to arrive at this outcome (with all code released as open source at the https://github.com/the-cyber-boardroom and the https://github.com/owasp-sbot repos)
Thanks for reading, please subscribe to the mvp.myfeeds.ai persona-driven newsletters and give me feedback and ideas on how to make it better :)
This final paragraph is here to make this article exceed 2000 words, as counted by the Ghost word counter to the right hand side of the editor